|
I will be joining Luma AI as a Research Scientist, working on image/video foundation models, multimodal models, and physical AI. Previously, I worked at Snap, where I led the RLHF direction for video generation. Before Snap, I was a Research Scientist at Meta, working on 3D vision and diffusion models. I received my PhD from Texas A&M University, where I was advised by Dr. Yoonsuck Choe. Email / CV / Google Scholar / Linkedin |

|
|
|
|
|
Research Scientist Jul 2026 - |
|
|
Machine Learning Engineer (GenAI) Jun 2025 - May 2026 |
|
|
Research Scientist Feb 2022 - Apr 2025 |
|
|

|
Brian Chao, Hung-Yu Tseng, Lorenzo Porzi, Chen Gao, Tuotuo Li, Qinbo Li, Ayush Saraf, Jia-Bin Huang, Johannes Kopf, Gordon Wetzstein, Changil Kim CVPR 2025 Project page / arXiv |

|
Chieh Hubert Lin, Changil Kim, Jia-Bin Huang, Qinbo Li, Chih-Yao Ma, Johannes Kopf, Ming-Hsuan Yang, Hung-Yu Tseng ECCV 2024 Project page / arXiv |

|
Jaehoon Choi, Rajvi Shah, Qinbo Li, Yipeng Wang, Ayush Saraf, Changil Kim, Jia-Bin Huang, Dinesh Manocha, Suhib Alsisan, and Johannes Kopf CVPR 2024 Project page / pdf We present a practical method for reconstructing and optimizing textured meshes of large, unbounded real-world scenes that offer high visual and geometric fidelity. |

|
Hung-Yu Tseng, Qinbo Li, Changil Kim, Suhib Alsisan, Jia-Bin Huang, Johannes Kopf CVPR 2023 Project page / arXiv We propose a pose-guided diffusion model to generate a consistent long-term video of novel views from a single image. |

|
Qinbo Li and Nima Kalantari SIGGRAPH Asia 2020 project page / pdf / video / code Synthesize light fields from a single image on general scene. Introduced a light field dataset that includes indoor and outdoor scene. |
|
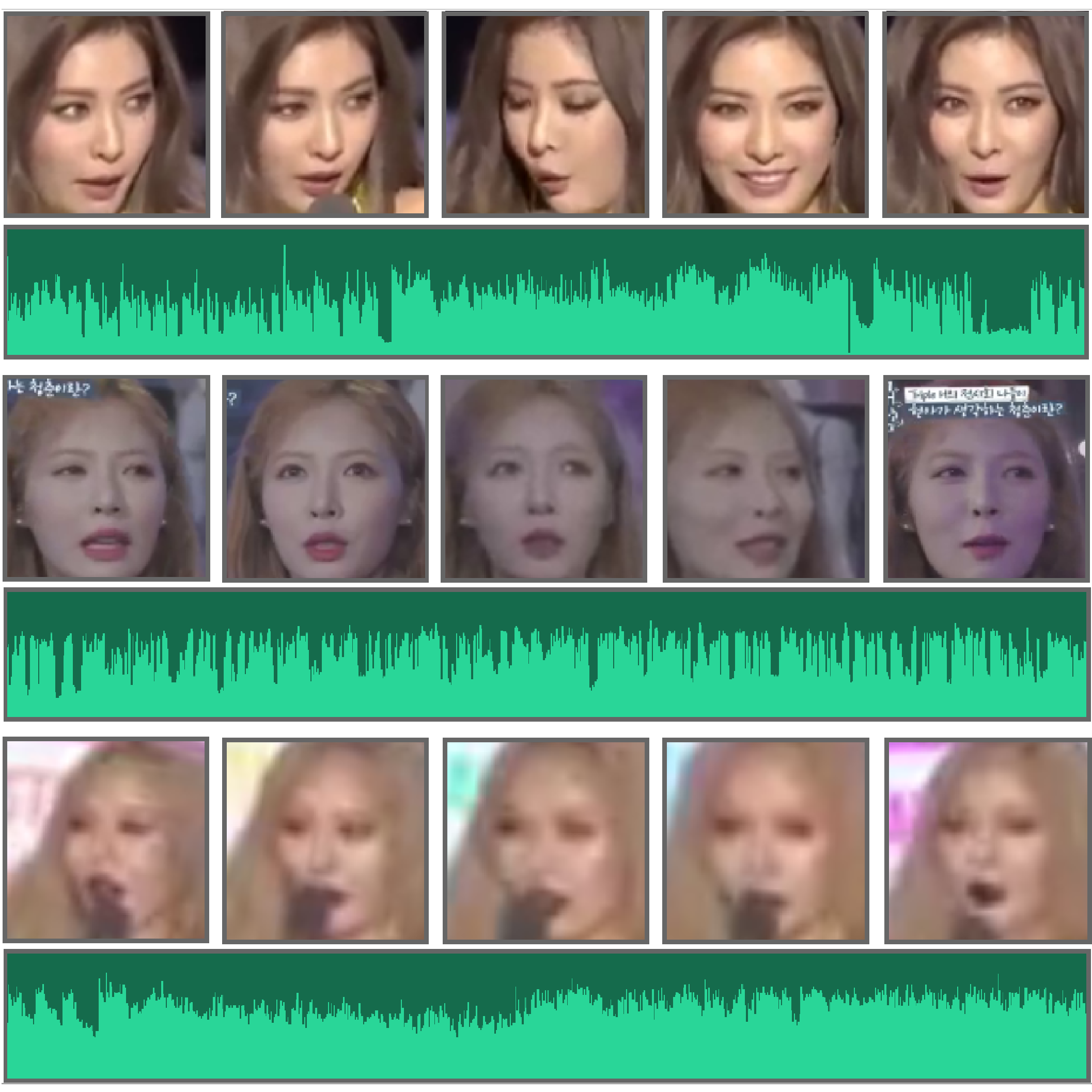
Qinbo Li, Qing Wan, Sang-Heon Lee, Yoonsuck Choe International Conference on Neural Information Processing 2021 We introduce an Audio-Visual Aggregation Network (AVAN) to aggregate multiple facial and voice information to improve face recognition performance. |
|
|
Construction and Use of Tools through Hierarchical Deep Reinforcement Learning
Qinbo Li and Yoonsuck Choe
IROS workshop 2021
Tool construction and use challenge: Tooling test rebooted
Yoonsuck Choe, Jaewook Yoo, and Qinbo Li
AAAI Workshop, 2015
|
Template from Jon
Barron, |